Imagine trying to teach a child about the world around them. You point to a dog and say, “This is a dog.” The child learns to associate that particular animal with the word “dog.” Over time, with more examples, the child learns to identify different breeds and sizes of dogs, even those they’ve never seen before. In the world of artificial intelligence (AI), this process is known as data annotation, a fundamental practice that allows machines to understand and interpret information like humans.
What is AI Data Annotation?
At its core, AI data annotation is the practice of tagging or labelling data. This labeled data is then used to train AI models, helping them to recognise patterns, make decisions, and understand the world similarly to humans. The data could be text from documents, objects in images, sequences in videos, or snippets in audio files. Each type of data requires a unique approach to annotation.
The Role of Data Annotation in AI
To understand the importance of data annotation, let’s take a trip down memory lane. Remember when you first learned to read? You didn’t just open a book one day and understand every word. You started with the alphabet, moved on to simple words, then sentences, and eventually, whole stories. This gradual learning process is similar to how AI models learn from annotated data.
For instance, consider a self-driving car. To navigate roads safely, it must recognise various objects like other vehicles, pedestrians, traffic lights, and road signs. This recognition is made possible through data annotation. Thousands of images of roads are manually labeled to indicate different objects. These labeled images are then used to train the AI model, teaching it to identify and react to these objects when it’s out on the road.
Types of Data Annotation
Data comes in various forms, and so does data annotation. Let’s explore the main types:
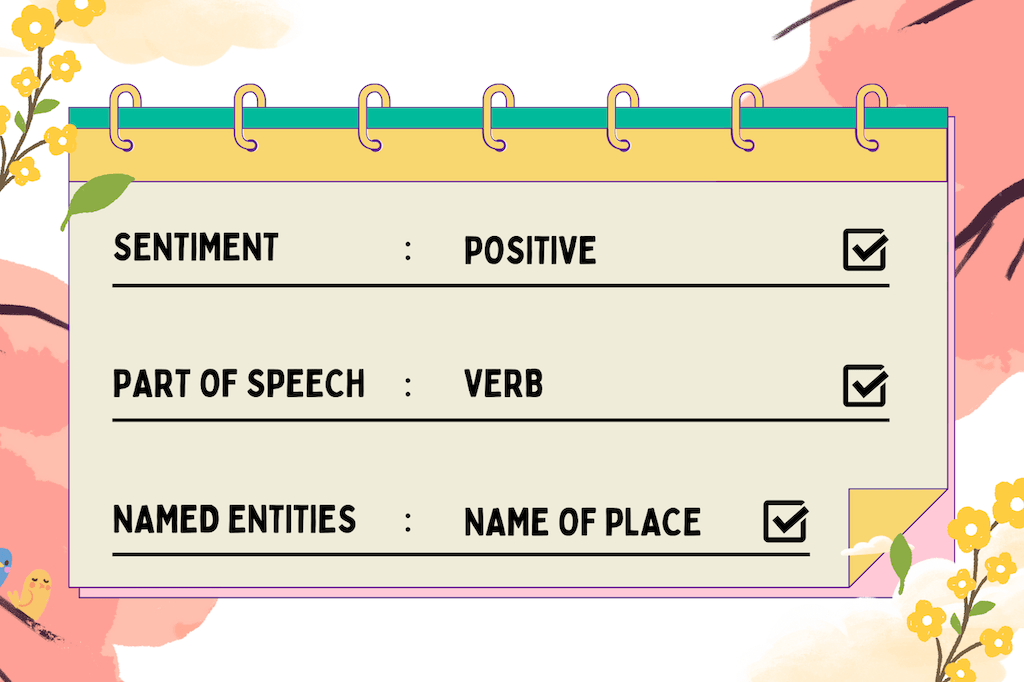
- Text Annotation: Imagine reading an email and being able to tell if it’s a spam or a genuine message. For AI to do this, it needs to understand the context of the text. Text annotation involves tagging words, phrases, or sentences with labels. These labels can indicate sentiment (positive, negative, neutral), parts of speech (nouns, verbs, adjectives), or named entities (names of people, places, organisations). This helps AI models to understand language nuances, enabling applications like chatbots, sentiment analysis, and spam detection.
- Image Annotation: Picture a security camera that can identify intruders. For this to work, the AI must learn to recognise various objects in images. Image annotation involves labelling objects within images, often by drawing bounding boxes around them. For example, annotating a street scene might involve labelling cars, pedestrians, and traffic lights. This type of annotation is crucial for developing technologies like facial recognition, medical imaging, and autonomous vehicles.
- Video Annotation: Think about how useful it would be to have a system that can monitor video footage and alert you to specific actions, like someone falling or a package being left unattended. Video annotation involves labelling sequences of actions or events within a video. This can be more complex than image annotation, as it requires tracking objects and actions across multiple frames. Video annotation is essential for applications such as surveillance, sports analytics, and video summarisation.
- Audio Annotation: Imagine having a virtual assistant that cannot only understand what you say but also detect different voices in a noisy room. Audio annotation involves labelling segments of audio files. This can include transcribing spoken words, identifying different speakers, or marking specific sounds like claps or sirens. Audio annotation is vital for developing speech recognition systems, virtual assistants, and call centre analytics.
The Journey of Data Annotation
The journey of data annotation is both fascinating and complex. It begins with the collection of raw data. This data is then meticulously labeled by human annotators. These annotators are trained to understand the context and apply the correct labels. The annotated data is then used to train AI models, enabling them to make predictions and decisions.
For example, let’s follow the journey of data annotation for an AI model designed to detect spam emails. First, a large collection of emails is gathered. Human annotators go through each email, tagging them as “spam” or “not spam.” They might also label specific phrases or words that are common in spam emails, like “free offer” or “click here.” This annotated data is then fed into the AI model, which learns to identify patterns and characteristics of spam emails. Over time, with more annotated data, the model becomes more accurate, efficiently filtering out spam from your inbox.
The Challenges of Data Annotation
While the concept of data annotation is simple, the process can be challenging. Here are some of the key challenges:
- Volume of Data: AI models require vast amounts of data to learn effectively. Annotating large datasets can be time-consuming and expensive. For instance, training an AI model to recognise objects in images might require millions of labeled images.
- Quality of Annotation: The accuracy of an AI model depends heavily on the quality of the annotated data. Inconsistent or incorrect labelling can lead to poor model performance. Ensuring high-quality annotation requires skilled annotators and robust quality control processes.
- Subjectivity in Annotation: Some types of data annotation, like sentiment analysis, can be subjective. Different annotators might label the same text differently based on their interpretation. This subjectivity can introduce inconsistencies in the data, affecting the AI model’s performance.
- Privacy Concerns: Annotating certain types of data, especially personal data like emails or medical records, can raise privacy concerns. It’s essential to implement strict data privacy and security measures to protect sensitive information.
The Future of Data Annotation
The field of data annotation is evolving rapidly. As AI technologies advance, so do the methods and tools for data annotation. Here are some trends shaping the future of data annotation:
- Automation: While human annotators are currently indispensable, there’s a growing trend towards automating the annotation process. AI models are being developed to assist human annotators, improving efficiency and reducing costs. For example, semi-automated tools can pre-label data, which human annotators then review and correct.
- Crowdsourcing: Crowdsourcing platforms are becoming popular for data annotation. These platforms distribute annotation tasks to a large pool of workers, speeding up the process. Companies like Amazon Mechanical Turk and Figure Eight (now Appen) are leading the way in crowdsourced data annotation.
- Specialised Annotation Tools: As the demand for high-quality annotated data grows, so does the development of specialised annotation tools. These tools are designed to handle specific types of data, offering features like collaborative annotation, real-time quality checks, and integration with machine learning pipelines.
- Ethical Considerations: With the increasing use of AI in various domains, ethical considerations in data annotation are gaining importance. Ensuring transparency, fairness, and accountability in the annotation process is crucial. This includes addressing biases in annotated data and implementing ethical guidelines for annotators.
Real-World Applications of Data Annotation
To appreciate the impact of data annotation, let’s explore some real-world applications:
- Healthcare: In healthcare, data annotation is used to develop AI models for diagnosing diseases. Annotating medical images, like X-rays or MRIs, helps train models to detect anomalies such as tumours or fractures. This can significantly improve diagnostic accuracy and speed, ultimately saving lives.
- Retail: Retailers use data annotation to enhance customer experiences. For instance, annotating product images and descriptions helps train recommendation systems that suggest items based on customers’ preferences. Text annotation of customer reviews can also provide insights into consumer sentiments, helping retailers make informed decisions.
- Finance: In the finance sector, data annotation is used for fraud detection. Annotating transaction data with labels indicating fraudulent or legitimate transactions helps train models to detect suspicious activities. This plays a crucial role in preventing financial fraud and ensuring secure transactions.
- Entertainment: Streaming services like Netflix and Spotify use data annotation to personalise content recommendations. Annotating movies, TV shows, and songs with metadata such as genres, actors, or artists helps AI models suggest content tailored to users’ tastes. This enhances user satisfaction and engagement.
- Autonomous Vehicles: Self-driving cars rely heavily on data annotation. Annotating images and videos of road scenarios, such as labelling other vehicles, pedestrians, and traffic signals, is essential for training autonomous driving systems. This enables self-driving cars to navigate safely and make informed decisions on the road.
Conclusion
AI data annotation is a pivotal practice that bridges the gap between raw data and intelligent machines. By meticulously labelling text, images, videos, and audio files, we enable AI models to understand and interpret the world as humans do. Despite its challenges, the field of data annotation is advancing rapidly, driven by innovations in automation, crowdsourcing, and specialised tools.
As we continue to explore the potential of AI, the importance of high-quality annotated data cannot be overstated. Whether it’s improving healthcare diagnostics, enhancing retail experiences, securing financial transactions, personalising entertainment, or developing autonomous vehicles, data annotation is at the heart of these transformative applications.
In this ever-evolving landscape, one thing is certain: the journey of teaching machines to understand like humans has only just begun. And as we navigate this journey, data annotation will remain a cornerstone of AI development, shaping a future where intelligent machines seamlessly integrate into our everyday lives.